Let’s talk about microservice architecture
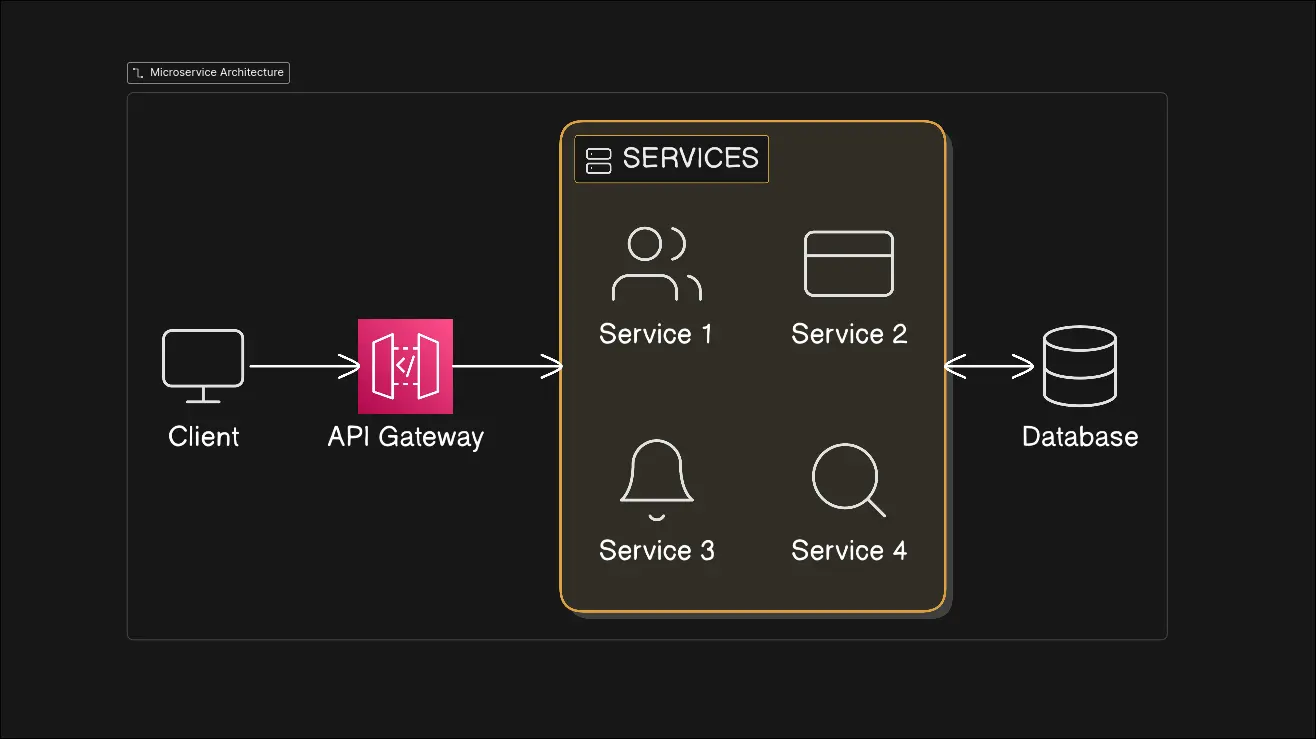
Look at the diagram first. Don’t read labels yet. Just observe the flow.
A client sends a request. That request does not directly hit business logic. It first goes through an API Gateway. From there, the request fans out to multiple independent services, and those services interact with the database.
That structure itself tells a story. Now let’s rewind and start from the problem.
As systems grow, one big application starts becoming painful. Every feature lives in the same codebase, shares the same deployment cycle, and often the same database. A small change in one module risks breaking something completely unrelated. Scaling becomes awkward. Teams start stepping on each other’s toes.
Microservices are not about splitting code. They’re about splitting responsibility. In a microservice architecture, instead of one giant application, the system is broken into small, focused services, each owning a single business capability.
In the diagram: Service 1 could be user management Service 2 could be payments Service 3 could be notifications Service 4 could be search
Each service does one thing and does it well. Now notice the API Gateway sitting in front of them. This is intentional.
The client doesn’t need to know how many services exist or where they live. It talks to one entry point. The API Gateway handles routing, authentication, rate limiting, and request coordination. It becomes the system’s front door.
From a design perspective, this gives you two huge advantages:
- You can change internal services without breaking clients
- You centralize cross-cutting concerns instead of duplicating them everywhere
Now focus on the services themselves. Each service runs independently. They can be deployed independently. They can be scaled independently.
If Service 3 suddenly gets heavy traffic, you scale only Service 3. You don’t touch Service 1, 2, or 4. This is the core promise of microservices: independent evolution. The database at the bottom completes the picture.
In real production systems, services often own their own data, even if the diagram shows a single database for simplicity. The important idea is ownership. A service should control how its data is read and written. Other services interact through APIs, not by poking into tables directly.
This avoids tight coupling at the data level, which is where most systems silently rot. Now let’s talk about why teams actually adopt microservices.
The biggest benefit is organizational scalability. Multiple teams can work in parallel. Each team owns a service. Each team deploys on their own schedule. Failures also become isolated.
If Service 4 goes down, the rest of the system may degrade gracefully instead of collapsing entirely. But microservices are not a free lunch.
They introduce: – Network calls instead of function calls – Distributed failures – Debugging across services – Operational complexity
That’s why microservices make sense only when the system and team size justify them. A small application does not need this. A growing platform absolutely does. So here’s the mental model to remember:
Monoliths optimize for simplicity. Microservices optimize for change.
The diagram captures that philosophy perfectly: A single entry point. Multiple independent services. Clear boundaries. Loose coupling.
Happy designing 🖤